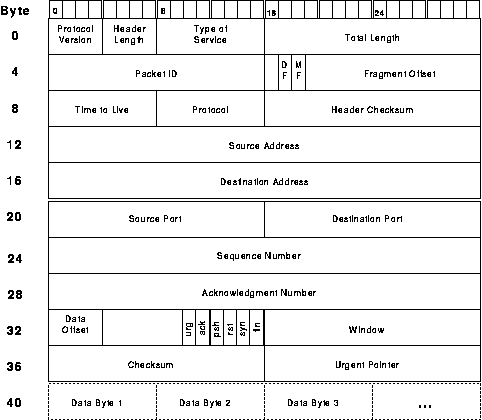
Figure 2 shows a typical (and minimum length) TCP/IP datagram header./7/ The header size is 40 bytes: 20 bytes of IP and 20 of TCP. Unfortunately, since the TCP and IP protocols were not designed by a committee, all these header fields serve some useful purpose and it's not possible to simply omit some in the name of efficiency.
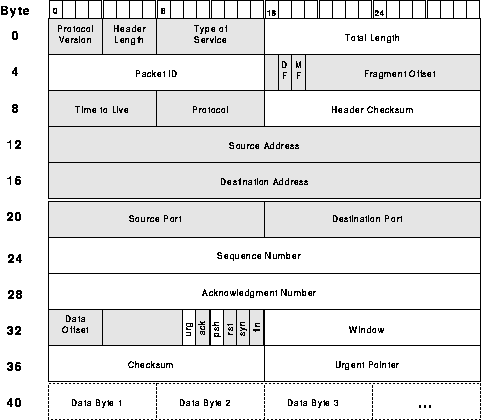
However, TCP establishes connections and, typically, tens or hundreds of packets are exchanged on each connection. How much of the per-packet information is likely to stay constant over the life of a connection? Half---the shaded fields in fig. 3. So, if the sender and receiver keep track of active connections/8/ and the receiver keeps a copy of the header from the last packet it saw from each connection, the sender gets a factor-of-two compression by sending only a small (<= 8 bit) connection identifier together with the 20 bytes that change and letting the receiver fill in the 20 fixed bytes from the saved header.
One can scavenge a few more bytes by noting that any reasonable link-level framing protocol will tell the receiver the length of a received message so total length (bytes 2 and 3) is redundant. But then the header checksum (bytes 10 and 11), which protects individual hops from processing a corrupted IP header, is essentially the only part of the IP header being sent. It seems rather silly to protect the transmission of information that isn't being transmitted. So, the receiver can check the header checksum when the header is actually sent (i.e., in an uncompressed datagram) but, for compressed datagrams, regenerate it locally at the same time the rest of the IP header is being regenerated./9/
This leaves 16 bytes of header information to send. All of these bytes are likely to change over the life of the conversation but they do not all change at the same time. For example, during an FTP data transfer only the packet ID, sequence number and checksum change in the sender->receiver direction and only the packet ID, ack, checksum and, possibly, window, change in the receiver->sender direction. With a copy of the last packet sent for each connection, the sender can figure out what fields change in the current packet then send a bitmask indicating what changed followed by the changing fields./10/
If the sender only sends fields that differ, the above scheme gets the average header size down to around ten bytes. However, it's worthwhile looking at how the fields change: The packet ID typically comes from a counter that is incremented by one for each packet sent. I.e., the difference between the current and previous packet IDs should be a small, positive integer, usually <256 (one byte) and frequently = 1. For packets from the sender side of a data transfer, the sequence number in the current packet will be the sequence number in the previous packet plus the amount of data in the previous packet (assuming the packets are arriving in order). Since IP packets can be at most 64K, the sequence number change must be < 2^16 (two bytes). So, if the differences in the changing fields are sent rather than the fields themselves, another three or four bytes per packet can be saved.
That gets us to the five-byte header target. Recognizing a couple of special cases will get us three byte headers for the two most common cases---interactive typing traffic and bulk data transfer---but the basic compression scheme is the differential coding developed above. Given that this intellectual exercise suggests it is possible to get five byte headers, it seems reasonable to flesh out the missing details and actually implement something.